Contexto real
No último ano, testei pipelines de APIs que utilizavam Large Language Models (LLMs) e frameworks como LangChain, em arquitetura RAG (Retrieval-Augmented Generation), em ciclos críticos de desenvolvimento. O cenário era comum para muitos setores: squads sob pressão para entregar features IA-driven, mas sem, necessariamente, o domínio técnico sobre os riscos e requisitos de validação de sistemas baseados em inteligência artificial generativa. Times de produto e backend demandavam testes automatizados mais “tradicionais”, esperando que baste validar status code ou payload. Só que, quando olhamos para sistemas que usam LangChain e RAG, validar apenas endpoints não mede a qualidade real — principalmente resultado, consistência e robustez perante updates de modelo ou de contexto.
Esse distanciamento de QA em relação ao funcionamento de IA generativa prejudica: 1) a assertividade dos testes, 2) a modelagem dos cenários edge case, e 3) a comunicação sobre riscos e limitações reais da solução, especialmente considerando vieses, hallucinations e atualizações dos embeddings no pipeline RAG.
Análise técnica
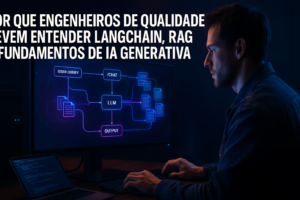
Quem trabalha com QA e engenharia de qualidade geralmente conhece automação API, testes E2E ou performance. Entretanto, em arquiteturas modernas, LangChain orquestra fluxos com múltiplos documentos, chains, calls para LLMs (OpenAI, Google, HuggingFace), bancos vetoriais como Pinecone ou Weaviate, além de fontes contextuais dinâmicas. O QA que ignora conceitos como retrieval, prompt chaining e os objetivos da RAG fica cego: não enxerga a raiz dos resultados variáveis, não projeta casos de teste que exponham limitações do modelo, e perde chances de validar de fato a “qualidade” do output em termos práticos.
Tomemos um pipeline real usando LangChain+OpenAI+Pinecone. Um endpoint “/chat” recebe perguntas complexas do usuário, roda o input num retriever que consulta documentos, monta contextos, invoca o modelo, pós-processa e retorna um texto. Testar só status ou a presença de campos no JSON não faz sentido. O correto é, além dos asserts de resposta, avaliar:
– COBERTURA de contextos (retriever está recuperando docs certos?);
– ROBUSTEZ perante atualização dos embeddings/vetores (mudanças de indexação alteram o resultado?);
– CONSISTÊNCIA do output (“alucina”? Reponde diferente para perguntas similares?);
– EXPOSIÇÃO de dados sensíveis via prompt injection ou falhas de chunking.
Quando usar:
– Sempre que a squad usar IA generativa, LLM APIs ou pipelines baseados em LangChain/RAG (ou similares).
– Em todas as etapas: desde testes unitários de componentes de chains até E2E simulando fluxos reais, inclusive no CI.
Quando NÃO usar (ou priorizar menos):
– MVPs ou PoCs internos onde a qualidade do resultado textual não impacta clientes externos ou compliance.
– Serviços auxiliares que não expõem outputs IA-driven para usuários finais (ex: logs internos, pipelines de enrichment).
Trade-offs:
– QA precisa investir em entender minimamente como funcionam embeddings, prompt engineering, e arquitetura dos retrievers para modelar casos de teste eficazes. Dá trabalho — mas sem isso, os testes serão sintáticos e farão pouca diferença.
– Inclui overhead e curva de aprendizado. Ferramentas de automação tradicionais (Postman, Cypress) precisam ser complementadas por scripts mais inteligentes, análises semânticas, ou benchmarks manuais com humanos no loop, pelo menos inicialmente.
Erros comuns
1. Tratar endpoints de IA generativa como APIs REST comuns: validar só status code ou response schema, sem analisar semântica do texto gerado, é inútil.
2. Não envolver pessoas com background em prompt engineering ou NLP nos design reviews nem na escrita dos casos de teste.
3. NÃO manter um baseline de outputs em diferentes versões de modelo/contexto. A QA que não versiona exemplos e não testa regressivamente se outputs mudam com update de modelo está deliberadamente aceitando riscos.
4. Ignorar attack vectors — prompt injection é real, e pipelines LangChain/RAG trazem riscos de exposure para informações sensíveis ou comportamentos inesperados.
5. Não criar ambientes de CI/CD que validem outputs LLM de modo automatizado, usando ferramentas como frameworks de golden test ou Comparators semânticos.
Conclusão prática
Se a engenharia de qualidade não entender, na prática, conceitos de LangChain e RAG, o time deixará vulnerabilidades e perderá chances de entregar software robusto, confiável e auditável. O QA precisa sair do trivial e, de fato, se envolver com arquitetura semântica e com validação customizada de pipelines IA-driven. Não é moda: é, literalmente, o que garante a confiabilidade, segurança e evolução sustentável do produto.
No cenário citado, só conseguimos detectar uma falha grave de prompt leaking porque testamos fluxos de pergunta-resposta usando input adversário, depois de mapearmos o chain. Teste “de prateleira” não teria pego. Para CI/CD, scripts que consultam a API e comparam outputs com golden sets são obrigatórios.
Minha visão: todo QA avançado precisa realmente entender, modelar e testar sistemas RAG/LangChain com outra mentalidade. Do contrário, será reduzido a mero validador de payload, deixando passar exatamente o que mais importa.
Referências
- “LangChain: Building LLM applications with composability as a principle”, https://python.langchain.com/docs/get_started/introduction
- “Retrieval-Augmented Generation (RAG): The LLM Stack That Actually Works”, https://sebastianraschka.com/blog/2023/rag.html
- “Securing LLMs against Prompt Injection Attacks”, https://owasp.org/www-community/attacks/Prompt_Injection
- “Pinecone Best Practices for QA”, https://docs.pinecone.io/docs/best-practices